If we toss a `fair’ coin, one for which heads and tails are equally likely, a large number of times, we expect approximately equal numbers of heads and tails. But what is `approximate’ here? How large a deviation from equal values might raise suspicion that the coin is biased? Surely, 12 heads and 8 tails in 20 tosses would not raise any eyebrows; but 18 heads and 2 tails might.

We will consider the more general case where we do not know the odds for heads and tails. After all, no coin is perfect, so we cannot be sure that it is fair. Suppose we toss the coin 


- How many times do we need to toss a coin to get an accurate estimate of the odds
Conditional Probabilities
The probability of two independent events 

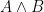
- The probability of
- The probability of
In symbolic form, this is

Now let us be specific and consider the event A to be “the occurrence of

Note that 
![{p\in[0,1]}](https://s0.wp.com/latex.php?latex=%7Bp%5Cin%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[p,p+dp]}](https://s0.wp.com/latex.php?latex=%7B%5Bp%2Cp%2Bdp%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

To answer the question posed above, we wish to estimate the first term in (1), that is, 
: The probability of odds
: The conditional probability of
: The probability of
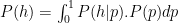
If we know the two factors on the right-hand side of (1) we can evaluate this integral.
We can now write an expression for the posterior probability:

This result is known as Bayes’ Theorem. It is often expressed in the form
![\displaystyle \left[ \genfrac{}{}{0pt}{}{\mathrm{Posterior}}{\mathrm{Probability}} \right] \propto \mbox {Likelihood} \times \left[ \genfrac{}{}{0pt}{}{\mathrm{Prior}}{\mathrm{Probability}} \right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cleft%5B+%5Cgenfrac%7B%7D%7B%7D%7B0pt%7D%7B%7D%7B%5Cmathrm%7BPosterior%7D%7D%7B%5Cmathrm%7BProbability%7D%7D+%5Cright%5D+%5Cpropto+%5Cmbox++%7BLikelihood%7D+%5Ctimes+%5Cleft%5B+%5Cgenfrac%7B%7D%7B%7D%7B0pt%7D%7B%7D%7B%5Cmathrm%7BPrior%7D%7D%7B%5Cmathrm%7BProbability%7D%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
There is a vast literature on Bayes’ Theorem, the many controversies that have surrounded it and its numerous applications. For an elementary account of this history, see McGrayne (2011).
Estimating the Terms
The prior probability 


This comes from the chance of 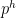

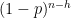

The integral 

We can now write the desired probability density function (2) in final form:
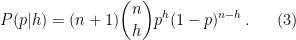
This looks like a binomial distribution but
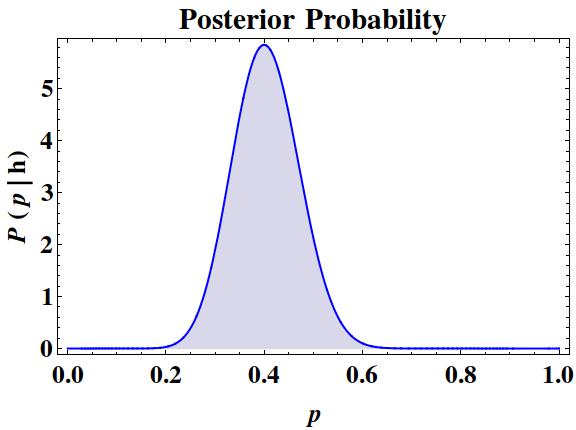
The figure below shows the posterior probability 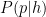
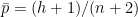
A Limiting Case
Before getting to the odds, we look briefly at a limiting case. Suppose we “know” a priori that the coin is fair (this is unrealistic but instructive). Then we must choose 
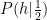

that is, the posterior probability is identical to the prior. Since we are certain from the outset, no amount of additional data can sway our conviction. But this never happens: no coin, however carefully minted, is guaranteed to be completely fair. In reality, we should consider a prior peaking sharply at 
How Many Tosses?
The question raised above was how many tosses are needed to estimate the odds. Of course, this depends on the level of precision required. The posterior distribution for

This is a standard beta distribution. The expected value of
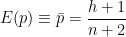
and its variance is

For large

The quantity 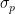
We expect 
![{[\bar p-\kappa\sigma_p,\bar p+\kappa\sigma_p]}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cbar+p-%5Ckappa%5Csigma_p%2C%5Cbar+p%2B%5Ckappa%5Csigma_p%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


![\displaystyle \kappa\sigma_p = \kappa\sqrt{\frac{\bar p(1-\bar p)}{n}} < \epsilon \qquad\mbox{or}\qquad n > \kappa^2 \left[\frac{\bar p(1-\bar p)}{\epsilon^2}\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ckappa%5Csigma_p+%3D+%5Ckappa%5Csqrt%7B%5Cfrac%7B%5Cbar+p%281-%5Cbar+p%29%7D%7Bn%7D%7D+%3C+%5Cepsilon+%5Cqquad%5Cmbox%7Bor%7D%5Cqquad+n+%3E+%5Ckappa%5E2+%5Cleft%5B%5Cfrac%7B%5Cbar+p%281-%5Cbar+p%29%7D%7B%5Cepsilon%5E2%7D%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Suppose the coin is approximately fair. Then 



This is amazing: we need on the order of a million tosses to have confidence in the estimated value of
If we ask for six-figure accuracy, we need a trillion tosses!
Sources
Sharon Bertsch McGrayne, 2011: The Theory that would not Die. Yale Univ. Press, 336pp.
