Next week there will be a post on tuning pianos using a method based on entropy. In preparation for that, we consider here how the entropy of a probability distribution function with twin peaks changes with the separation between the peaks.
Classical Entropy
Entropy was introduced in classical thermodynamics about 150 years ago and, somewhat later, statistical mechanics provided insight into the nature of this quantity. Further insight came with the use of entropy in communication theory. This allowed entropy to be understood as missing information.
Suppose a variable 
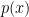




However,
![\displaystyle p(x) = {\textstyle{\frac{1}{2}}}[ N(x,\mu_1,\sigma_0) + N(x,\mu_2,\sigma_0) ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28x%29+%3D+%7B%5Ctextstyle%7B%5Cfrac%7B1%7D%7B2%7D%7D%7D%5B+N%28x%2C%5Cmu_1%2C%5Csigma_0%29+%2B+N%28x%2C%5Cmu_2%2C%5Csigma_0%29+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Now suppose 

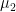


Differential Entropy
We need a better measure of the missing information. It is provided by the differential entropy (also called the continuous entropy)

For the normal distribution, we can evaluate the integral, with the result that
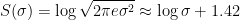
So we see that 
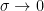
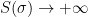

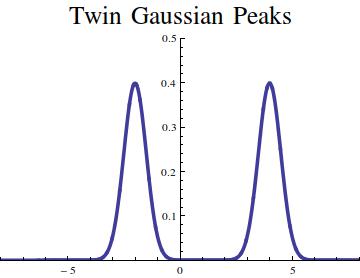
Let us consider the average of twin peaks, one centered at the origin, the other at
![\displaystyle p(x) = {\textstyle{\frac{1}{2}}}[ N(x,0,1) + N(x,\mu,1) ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+p%28x%29+%3D+%7B%5Ctextstyle%7B%5Cfrac%7B1%7D%7B2%7D%7D%7D%5B+N%28x%2C0%2C1%29+%2B+N%28x%2C%5Cmu%2C1%29+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
When the peaks coincide, 



In conclusion, we see that a single Gaussian peak has lower entropy than two separated peaks. As the separation grows, the entropy tends to a limit whereas the variance grows without bound.
Next week’s article will apply these entropy ideas to the practical problem of piano tuning!
