We live in the age of “big data”. Voluminous data collections are mined for information using mathematical techniques. Problems in high dimensions are hard to solve — this is called “the curse of dimensionality”. Dimension reduction is essential in big data science. Many sophisticated techniques have been developed to reduce dimensions and reveal the information buried in mountains of data.

We will look at the method of principal component analysis (PCA). This method identifies a small number of new variables called principal components that allow us to spot patterns. It also allows us to visualize the data in a simple two-dimensional diagram that often illustrates the core factors of a problem.
PCA has many uses: an intriguing application in genetics, showing how DNA can be used to infer an individual’s geographic origin with remarkable accuracy will be described next week [Reference to follow]. Here we look at the underlying mathematics.
The Maths of Principal Component Analysis (PCA)
For a collection of points in a high-dimensional space, we can find a `line of best fit’, PC1, that minimizes the average squared distance from the points to the line. We can then choose another best-fitting line, PC2, perpendicular to the first, giving the plane that best fits the data. Continuing, we get an orthogonal basis of uncorrelated basis vectors, called principal components. Principal Component Analysis (PCA) can be done by calculating the covariance matrix 
We begin by considering how to diagonalize the covariance matrix. Suppose that 
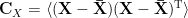
For simplicity, we move the origin so that 
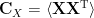



But the matrix 

with orthogonal eigenvectors 





We assume the eigenvalues 
Singular Value Decomposition (SVD)
The fundamental theorem of linear algebra concerns matrix mappings between vector spaces. It may be stated concretely in terms of the singular value decomposition of a matrix. Any 


Here, 
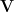
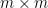
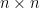

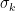


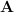 .
.Suppose now that our data matrix 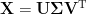
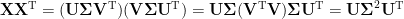
We see the correspondence with the above approach: 

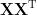
The SVD is reviewed by Gilbert Strang (1993), who describes how, associated with each matrix, there are four fundamental subspaces, two of 

SVD has a wide range of applications in pure and applied mathematics and statistics. An application in compression of fingerprint images is described in an earlier post to this blog.
Sources
Gilbert Strang (1993): The Fundamental Theorem of Linear Algebra. Amer. Math. Mon, 100, 848–855.
