In many fields of mathematics there is a result of central importance, called the “Fundamental Theorem” of that field. Thus, the fundamental theorem of arithmetic is the unique prime factorization theorem, stating that any integer greater than 1 is either prime itself or is the product of prime numbers, unique apart from their order.
The fundamental theorem of algebra states that every non-constant polynomial has at least one (complex) root. And the fundamental theorem of calculus shows that integration and differentiation are inverse operations, uniting differential and integral calculus.
The Fundamental Theorem of Linear Algebra
In linear algebra, the fundamental theorem concerns matrix mappings between vector spaces. It may be stated concretely in terms of the singular value decomposition of a matrix. Any 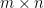
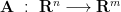
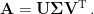
Here, 
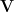
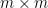
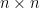
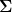
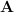
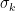

This singular value decomposition or SVD of a matrix has many wonderful properties and a wide range of important applications. The SVD is reviewed by Strang (1993) who describes how, associated with each matrix, there are four fundamental subspaces, two of 

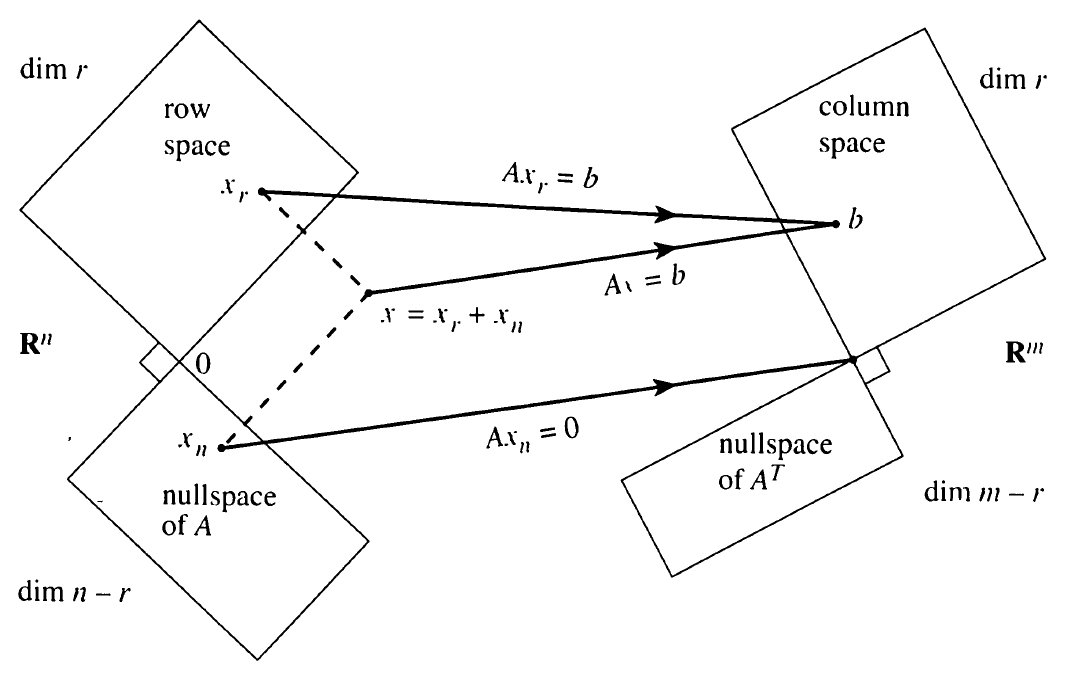
SVD provides perfect bases for the four fundamental subspaces. The first r columns of 



SVD and Data Compression
SVD has a wide range of applications in pure and applied mathematics and statistics. We will describe just one application, its use in image compression.
The matrix 
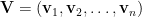

This is known as an outer product expansion, and each term is a rank 1 matrix.
By convention, the singular values are ordered: 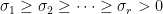

Imagine a satellite image comprising 1000 x 1000 pixels. The brightness of each pixel is described by a single number, so 1,000,000 numbers must be sent to transmit the image. However, there is often redundancy, and SVD allows us to exploit this. The redundancy manifests itself in terms of small singular values. If we need to retain only the first 50 terms in the outer product expansion, then only the values in 
Application to Fingerprint Images
On the website of John Burkardt of FSU there is a Matlab program that reads a file containing a fingerprint image and uses SVD to compute a series of low rank approximations to the image. The outer product expansion is truncated at various ranks



The original image was 400 x 480 pixels, so 400 singular vectors would be required for an exact reproduction. The image on the right panel of the bottom figure uses only 40 singular vectors and still manages to produce the essential features of the original image.
It is clear that, although they have a great deal of fine detail, fingerprint images can be effectively compressed using SVD. This is just one of a multitude of “singularly valuable” applications of SVD.
Beautiful, Useful and Fun
This blog aims to show that mathematics is beautiful, useful and fun. The singular value decomposition has all these qualities. It is very elegant, and has a wide range of useful applications. Now have some fun and answer the following questions:
- What are the eigenvalues and eigenvectors of
?
- What are the eigenvalues and eigenvectors of
?
- To what form does the SVD reduce when the matrix
Reference: Gilbert Strang (1993): The Fundamental Theorem of Linear Algebra. Amer. Math. Mon, 100, 848-855.
